XGBoost源于boosting tree,全称“Extreme Gradient Boosting”。算法原理参考推荐XGBoost的slides和论文,尤其是slides,非常形象易懂,很精彩。本文是对XGBoost核心公式推导与关键点的思考总结。
核心公式推导
- 第$t$轮目标函数
- 泰勒展开公式
- 目标函数的泰勒展开
- 去掉常数项
- 定义树,$w$表示叶子得分,$q$函数把样本分配到叶子结点
- 正则项,定义树的复杂度。这里惩罚$w_j$的原因?个人理解:正则项的目的是为了防止过拟合,增强模型的泛化能力。boosting tree的预测结果是众多子树预测累加得到的,对$w_j$限制是为了让每颗树都变得‘平庸’,加入某颗树某个叶子得分异常高,它会严重压缩其他树的空间,并对最终预测结果起重要影响,如果碰巧这颗树又不小心过拟合了,进而造成该类预测过拟合。
叶子结点的实力集合
化简至叶子单位
求导,获得最优解
贪心求解,定义增益公式,获得最佳分裂点,分裂得到左叶子和右叶子
稀疏切分
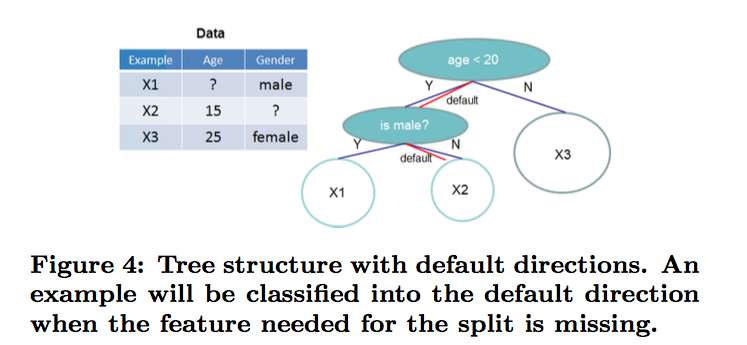
当样本的第i个特征值缺失时,无法利用该特征进行划分时,XGBoost的想法是将该样本分别划分到左结点和右结点,然后计算其增益,哪个大就划分到哪边
总结
- Shrinkage and Column Subsampling
Shrinkage降低了单颗树的影响,为future trees留下了更多生长空间,进而提升模型(这个在gbdt里也是有的)
Column Subsampling,就是特征采样,这个在随机森林里用到。根据用户反馈,特征采样比样本采样更能防止过拟合。 - 添加了对稀疏数据的处理。
- Column Block for Parallel Learning
就是以特征值为key,对样本进行了一次索引,并对特征值进行排序,存入内存中,称为‘block’。在树训练过程中,最耗时的是寻找最佳分裂结点,这个过程需要对数据排序,有了‘block’,这个过程的耗时就会大大减少,这是并行化的基础,可以看出xgboost是在特征粒度上实现并行的。 - 目标函数优化利用了损失函数关于待求函数的二阶导数
- 交叉验证,early stop,当预测结果已经很好的时候可以提前停止建树,加快训练速度,一定程度防止过拟合
- 支持设置样本权重,该权重体现在一阶导数g和二阶导数h,通过调整权重可以去更加关注一些样本