Wide & Deep 是Google Play推荐系统的排序模型,它旨在获得记忆(Memorization)和泛化(Generalized)的能力,克服线性模型和deep模型的缺点,并融合二者的优点,这是一个简单高效的排序模型,在当前工业界广泛使用。
- 记忆(Memorization)能力: 推荐的物品和用户行为主题非常相关,Exploitation
- 泛化(Generalized)能力:强调推荐物品的多样性,Exploration
记忆和泛化就像推荐系统的E&E,是利用和探索间的trade-off。
线性模型具有简单、可扩展和可解释性强等优点,经常用于训练one-hot编码后的稀疏矩阵,当然我们也可以构造交叉特征组合,具有不错的记忆能力,但是它的缺点就是无法发现用户行为中未出现的特征组合,缺乏泛化能力。
基于Embedding的模型,;例如分解机或者deep模型,可以在较少特征工程的前提下,泛化出之前未曾出现过的行为特征组合。但是因为用户的行为往往是非常稀疏的,以大稀疏矩阵做训练输入,无法有效更新deep模型的参数,往往造成deep模型的过拟合,使得推荐效果很不相关,缺乏记忆能力。
模型结构
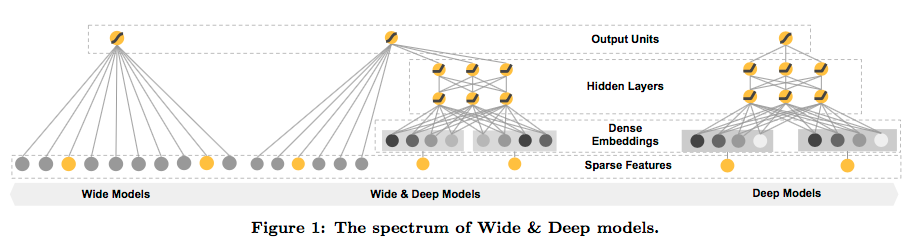
Wide模型
Wide模型就是一个广义线性模型,文中还提到一个最重要的特征处理是做特征的cross-product转换,这使得生成线性模型增添非线性的特质。
Deep模型
Deep模型就是一个简单的前馈神经网络,如上图右侧所示。对于稀疏、高维的类别特征,首先需要将其转换为低维,稠密的Embedding向量,向量维度一般取O(10)~O(100)。Embedding向量随机初始化,并通过最小化损失函数而不断训练。模型激活函数采用ReLU。
Joint Training联合训练
Wide组件和Deep组件通过weighted sum的方式结合,然后流经一个普通的logistic损失函数实现联合训练。文章特意指出了Joint Training和Ensemble之间的区别。
Ensemble这个词,想必打数据挖掘比赛的童鞋都会非常熟悉,使用多个模型分别训练,然后根据模型间的差异性、本地cv和线上表现进行融合,往往会获得不错的提升,但可以看出,各个模型间在训练期间是没有任何联系的。相反,Joint Training是在训练期间通过同时考虑多个模型和融合权重来优化所有模型参数。这对模型大小也是有意义的,对于Ensemble,因为模型间是独立的,所以单模型通过需要足够大才能获得不错的效果。而对于Joint Training,wide部分只需要以较小数量的cross-product特征转换来弥补deep部分的弱点,而无需实现一个全尺寸(full-size)的wide模型。
Joint Training通过使用mini-batch梯度优化进行反向传播来完成Wide模型和Deep模型的训练,融合模型公式如下。
系统实现
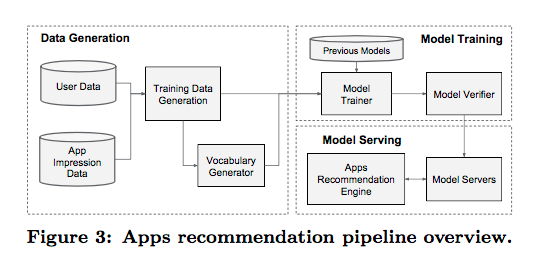
数据生成
- 二分label: app是否被下载
- 特征处理:
- ID映射
- 频次阈值过滤
- float特征归一化
模型训练
参数设计如下图:
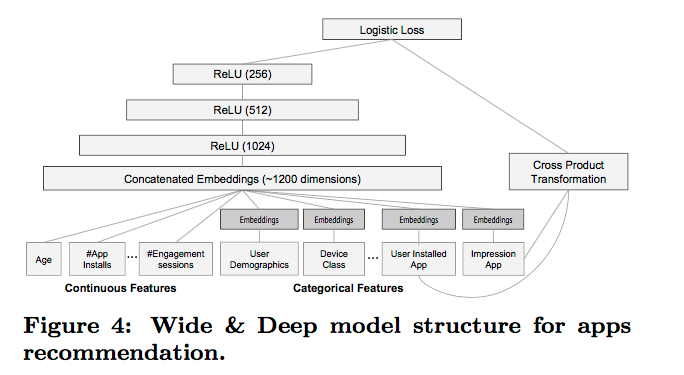
因为当新数据来时,模型需要重新训练,但是一次完整的训练是非常耗时的,这推迟了从获得新数据到线上模型更新的时间。采用warm-starting解决该问题,每次训练以前次训练的参数初始化,这会大大加速模型的拟合时间。
模型服务
通过多线程并行小批量预测提速
思考
wide & deep 简单有效,这个特点是生产环境的最爱。它融合线性模型与深度模型的各自优势,获得了很不错的线上提升,这也是融合的魅力。三个臭皮匠赛过诸葛亮,融合通过取长补短,往往能取得 1 + 1 > 2的效果。
在数据挖掘比赛里,多个差异化的优秀单模型融合往往能取得boost,这是打比赛的常规套路。不过在工业生产环境对模型的资源效率要求很高,如训练和预测时间、耗费的机器资源等,所以多模型Ensemble在生产环境下比较危险,优秀的单模型更加有效。这里,wide & deep模型就提供了另外一种思路 —- 差异化多模型的Joint Training。
wide模型和deep模型各有所长,又各有所短,差异化明显,通过Joint Training将二者融合在单模型中,不仅满足了生产环境的苛刻资源要求,又取得了融合的效果,一举两得。
参考
Wide & Deep Learning for Recommender Systems