Embedding实践:从word2vec到Topic2vec
自从Google word2vec广泛应用以来,Embedding的思想变得空前流行,已经成为深度学习不可或缺的一部分。Embedding是用一个低维向量来表征特征,可以将原来高维稀疏表示转换为低维稠密的向量表示。Embedding一般是神经网络训练的中间层结果,它在空间的位置和相互间的物理距离是具有意义,例如对于word2vec的训练出来的单词表征Embedding,对于像单词France和Paris这种有关联意义的单词,它们的空间距离是很近的,更有趣的是,还可以进行具有现实意义的向量运算,比如可以发现vec(Madrid) - vec(Spain) + vec(France) 和 vec(Paris)距离非常近。
在推荐系统应用中,我们也对Embedding应用进行了实践,从word2vec到item2vec,从item2vec到我们改进而来的topic2vec。整个实践过程都可以感受到word2vec的魅力,简单而有效。word2vec其实包含了协同的思想,协同过滤如ItemCF就是通过统计用户行为中的物品共现模式来获得物品相似矩阵,但它因为只局限于两个结点之间,泛化能力受到局限。有不少针对这个的缺点改进,如Simrank、SVD++等,就个人实践经验来说,大都华而不实,在算法落地中的表现都比较一般,且耗费较多的计算资源,反而不如ItemCF的整体收益,而Embedding思想正好弥补了ItemCF泛化能力弱的缺点,二者优劣互补,结合使用能取得1 + 1 > 2的效果。
Word2vec原理
Word2vec的训练方式有两种CBOW(Continuous Bag-of-Words)和Skip-gram两种方式:
- CBOW 基于相邻的词决定当前词
- Skip-gram 当前词决定相邻的词
从我们实践效果来说,Skip-gram效果更好,这里只总结Skip-gram原理,NN结构如下图所示:
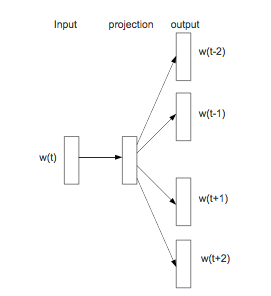
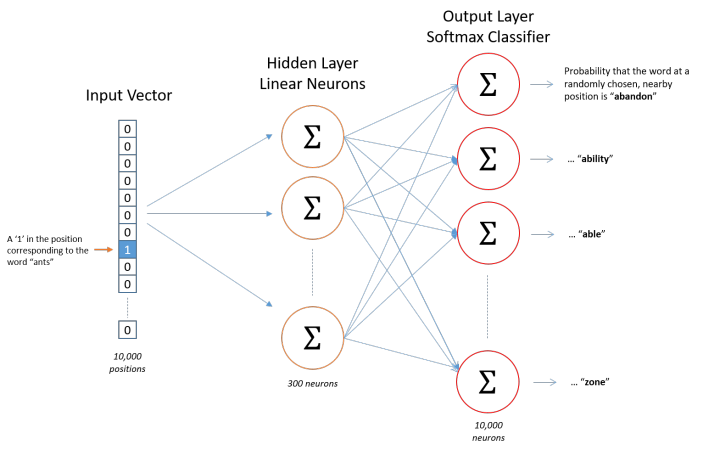
Skip-gram模型的训练目标是搜寻可以有效预测文档或句子附近词汇的单词表征(也就是Embedding)。对于一个训练词串$w_1, w_2,…,w_T$,其目标就是最大化平均log概率,公式如下:
通过softmax函数定义 $p(w_{t+j} | w_t)$, 公式如下:
然后$W$是词典大小,直接运算是不现实的,于是作者应用Hierarchical Softmax和负采样(negative sampling)来解决该问题,这里只总结负采样原理。
Negative Sampling
不同于原来每个训练样本都更新所有的权重,负采样只更新部分权重,可以巨幅降低计算量,且可以得到近优效果。Negative Sampling(NEG)的目标函数如下:
对比上面的公式,可以看到时间复杂度从$W$降低到了采样数$k$,采样公式采用一元模型分布(unigram distribution),这里采样的概率和单词出现的频次有关,出现的频次越高,越容易被选作负样本,采样公式如下, 其中3/4是经验值:
Item2vec
Word2vec的Skip-gram模型其实就是协同的思想,我们可以自然而然地迁移到用户行为序列中,就是把行为物品比作了单词,原理和word2vec完全一致。论文里拿Item2vec与SVD++作了一个简单的小对比,实验结果Item2vec效果更好。
对比ItemCF,Item2vec有更好的泛化能力,我们可以基于训练出来的item Embedding,召回邻近topK items,这突破了ItemCF邻域关系的限制。
在我们具体实践中,也察觉出Item2vec的弊端:
- 无法解决覆盖率问题,在合理阈值下,只能覆盖出现在用户行为序列中的物品集,但对于低频物品和新物品,还是没有召回结果的。
- 虽然覆盖率略高于ItemCF,但点击率低于ItemCF,整体收益仍是负向的,位置比较尴尬。
Topic2vec
基于实践所得经验,我们认为ItemCF不能被单纯替代,而应该以互补策略来对ItemCF进行补充。协同过滤的最大弊端就是受用户行为数据集所限,往往无法覆盖全量候选集。最简单的方式就是以内容过滤互补,内容过滤可以做到100%覆盖率,不过内容过滤在合理内容关联阈值限制下,召回结果同质化比较严重,泛化能力非常弱。于是我们思考能不能既满足100%覆盖率,又能具有学习用户行为模式的泛化能力,这里就有了Topic2vec。
Topic2vec是对Item2vec的延伸,它将Item实体替换为表征Item的特征,Item实体是有时间周期的,具体的。而特征在很长一段时间内都是稳定的,是可以重组泛化的。我们在Item2vec网络之前再加入一层特征表示层,用于表征Item实体。初始化各特征的Embedding后,我们以weighted-mean的方式融合Embedding,剩下的流程与word2vec一致,训练后我们可以得到各特征的Embedding,通过weighted-mean融合可覆盖全量Items,而训练的过程又是拟合用户行为模式的过程,这里就取得了我们上面提到的效果,网络结构如下图所示:
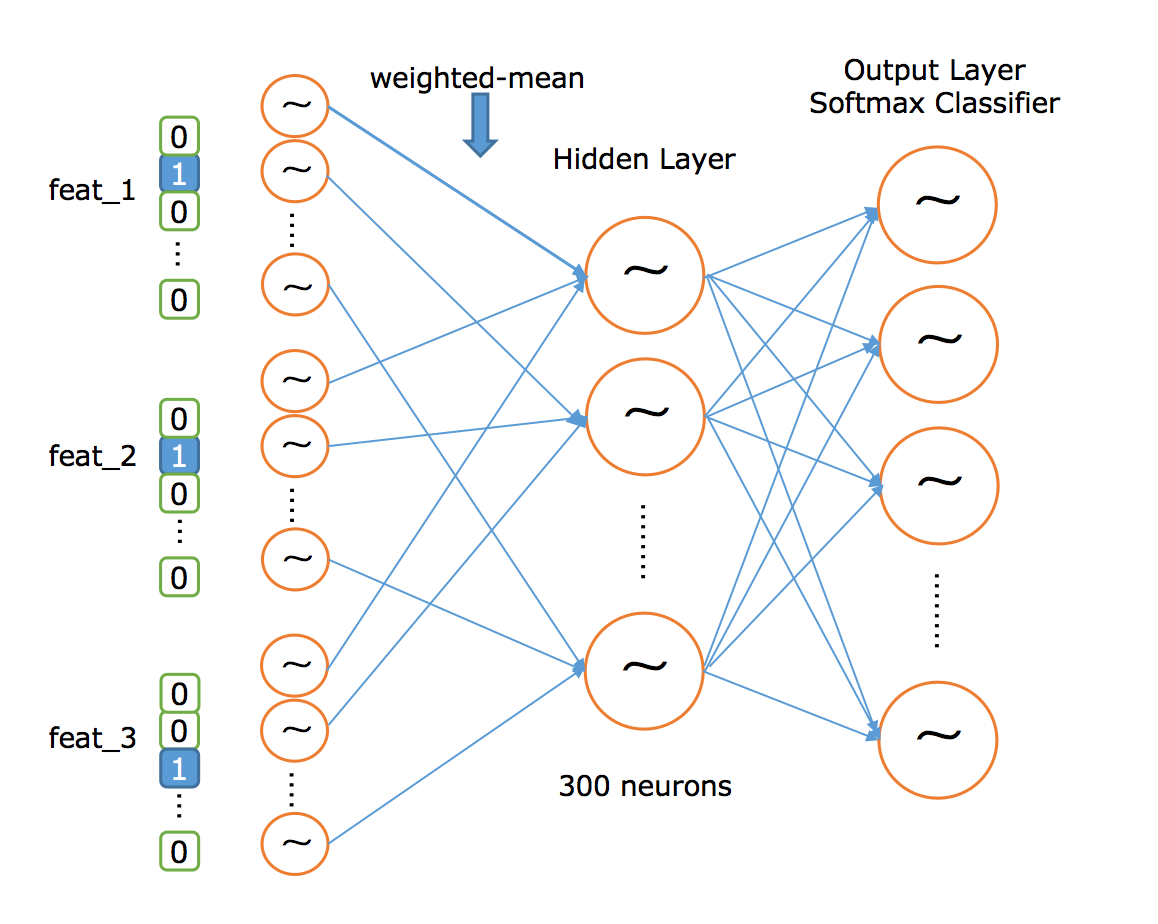
在实现中,我们使用tensorflow的 embedding_lookup_sparse api来计算weighted-mean,它可以再给定id和权重后,计算embeddings。
Topic2vec既能覆盖全量Items,又具有不错的泛化能力,在具体实践中,我们将Topic2vec作为ItemCF的后补策略,二者结合使用,取得不错的线上效果了。