最近终于整体完结了kaggle ELO比赛(比赛+远程答辩),我们队伍(TH & daishu & Q)最终排名4/4126,第一次进入Kaggle奖金区和经历Kaggle英文答辩,非常有意义,感谢我的队友TH与袋鼠,他们非常专业,本文对比赛所得作下小结。
ELO比赛是根据用户以往的行为历史数据来预测该用户的忠诚度。这个比赛private leaderboard揭晓后,经历了Big Shakeup,不少public榜前排的选手跌落下去,这种剧烈的shakeup也在我们的意料之中,这一切源于这个比赛的数据分布的怪异与评价指标RMSE的设定,该比赛的关键点:
怪异的数据分布
在train数据集里,绝大部分target都分布于-1~1之间,却有2000多个target为-33.21928的异常数据,结合该题的评价指标RMSE,这些异常数据的破坏力是决定性的,多预测正确数个异常点就能带来巨大的收益。思索主办方这样设定数据的意图,-33.21928代表了ZERO忠诚度的用户,这部分用户对主办方的业务意义重大。
这个怪异的数据分布也给这个比赛增加了戏剧性和技巧性,数个异常点的校正就可以带来排名不小的提升,许多队伍沉迷【改值post-process】不能自拔,这也为后来的shakeup埋下伏笔。
模型框架
针对如此异常的数据分布,我们设计了如下模型框架:
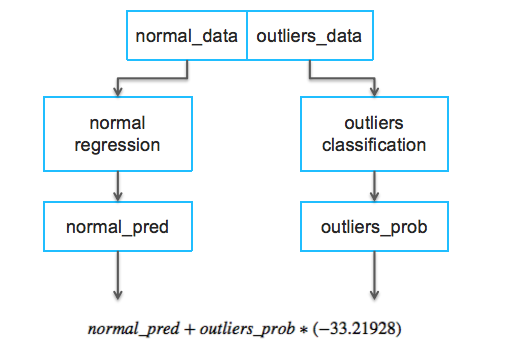
- 训练二分模型预测异常数据的概率,这里异常数据标注为1,非异常数据标注为0
- 只使用正常数据训练回归模型(消除异常数据对模型的异常影响)
- 通过binary模型和regression模型的结合拟合最终RMSE评价指标
通过该模型框架,我们让Local cross validation score得到了可观的提升。
特征工程
特征为王,特征工程的优秀与否具有决定性作用,我们队伍基于对数据的分析、业务推断和特征模式构造了大量细致的特征工程,整个过程比较艰苦和琐碎,细节不再详述。这里提一类有新意的特征模式,超多类别特征的Embedding降维。
对于类别特征,一般用one-hot编码来搞定,或者用Lightgbm的category训练入参,对于只有几十个类别的特征还是比较适合的,而对于拥有上万个或者几十万类别的特征,我们可以尝试用Embedding的方式来构造,它可以捕捉到统计型特征捕捉不到的东西。
在Elo比赛里,我们对purchase_date、merchant_id,purchase_amount作了Embedding化处理,使用的方式是Word2vec,LDA,PCA,NFM等,其实Embedding就是一种降维的方式,使用这种方式的前提是该特征中存在大量相同的值。比如purchase_amount,它本身是非常强力的特征,充分挖掘它的潜力非常重要,它虽然是一种数值特征,但是在千万行数据中,却只存在20w+个不同的purchase_amount值,存在大量相同的值,通过Word2vec进行Embedding降维,提取差异化特征,我们取得了不错的收益。
后处理
前面提到异常值带来的巨大收益,许多队伍都冒险选择了后处理,这也导致了最后private leaderboard的Big Shakeup。不少队伍的后处理方式就是对本地预测属于异常值的高概率的数据进行改值,直接赋值-33.21928,而很巧public leaderboard正好契合了某些改值手段。
这种陷阱被调侃为”蜜罐”,新手是无法拒绝这种诱惑的,我们在最后关头还在犹豫是不是要提交一个改值版本。我们综合计算了风险与收益,结合最终的RMSE评价指标,作了以下判断:
- 因为头部的预测概率已经足够高,改值带来的风险约是收益的三倍
- 本地交叉验证不支持改值收益理论
- 二分模型AUC比较糟糕,0.91+,对于如此不平衡的数据,这个AUC的置信度是很一般的,也说明了异常值预测的困难程度,在如此二分模型的基础上改值,无异于走钢丝。
综上,我们最终放弃了改值,提交了两个有些差异的submission,最终排名第四并选中了最优解,这也验证了我们的推断。
Trust Local CV
请相信你本地的交叉验证得分—-Trust Local CV。在各种比赛里,Trust Local CV一次次验证着它的正确,CV代表着你的数据模型的泛化能力与鲁棒性。一般而言,test数据是少于train数据,而public board的数据量一般又小于private board的数据量,正确的CV能较好的衡量你的数据模型在train这个量最大的数据集上表现,从概率的角度来看,CV的可信度明显强于public board。当然也会有异常的情况,这需要我们根据经验来判断和抉择了。
远程答辩
Elo比赛前5名属于奖金区,需要进行远程英文答辩,第一次和kaggle与比赛主办方通过Google Meet进行比赛交流,整个过程虽然有些紧张但也比较顺利,ELo工作人员还特意问道了对purchase_amount的Embedding的意图与动机。
最后
复盘整个比赛,收获颇多,这也是数据的魅力。在这个过程中我们通过特征、模型与技巧来拟合数据的规律,发现其中的奥秘,仿佛探案一般,还原数据的真相,非常有趣。
Kaggle厉害的选手有很多,不乏工作多年的资深数据科学家,这次能在Kaggle拿到奖金,十分不易,全靠团队优秀的协作配合,感谢队友TH和袋鼠。