Santander Customer Transaction Prediction,Kaggle有史以来参赛人数最多的比赛,反作弊后共有8802个队伍,9838人参与,真是万人空巷了。我们队伍参赛时间共20多天,最终排名12/8802。这个比赛Kaggle表格题大佬几乎尽出,GM高手过招,最终能拿下这个排名还是很高兴的,感谢队友TH、Daishu和包大人,本文对比赛历程作以小结。
看似简单的数据
Santander比赛是一个匿名特征赛,这个比赛之所以参赛人数如此众多,有一部分原因是它看似简单的数据:
- 数据量小,train + test = 40w
- 200维的匿名特征处理起来很平滑,上手容易
但比赛难度不是数据难度决定的,而是参赛选手决定的,万人的参与让整个比赛异常惨烈,尤其是最后几天Top排名竞争到了白热化的程度。整个比赛充斥着谜一般Magic,下面说一下我们发现Magic的历程。
Magic
首先说一下我对Magic特征的定义:能带来巨幅提升的简单特征簇。该比赛评价指标是AUC,在我们进入比赛的初期,top30的Public AUC score都在901以上,而且波动巨大,top1的甚至在924,后面几千名都在901以下,这种怪异的排名明显存在Magic特征。
我们发现如下线索:
1. 对正负样本数据分别作特征shuffle作数据增强有正向收益,
- 有收益说明数据增强的数据是符合原数据规律的,数据增强增加了训练样本,降低了泛化误差。
- 推测正负样本是根据特定分布Roll选出来的,所以shuffle产生了作用。
2. Test数据中存在fake data
- 有一个非常聪明的开源kernal推测当该行不存在一个特征值是唯一的,该行就是虚假数据,kernal给出的fake data正好10w个,这个数字太规整了,我们断定这个假设是正确的。
- 识别Fake data非常重要,对于Magic,它们充当的角色就是噪声,10w噪声,足以破坏Magic
3. 数据集中的Float特征存在大量相同的值
- train和test的特征值都保留四位小数,明显进行了截取,多个特征都存在大量相同的值,以至于许多队伍都把这个Float值当做类别处理
- 对同值Float特征作count特征,观察多个特征的count分布,我们发现正负样本分布存在细小差异,且形状贴近正态分布,如下图所示:
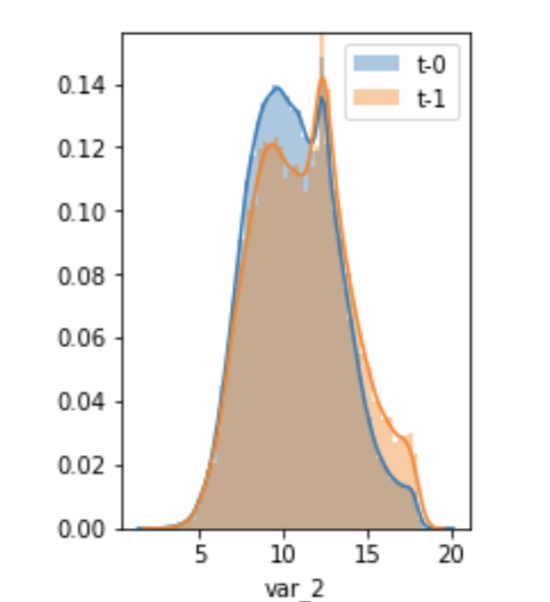
当我们把count值作为特征进行测试后,AUC 0.901->0.902,和0.91+与0.92+仍然相去甚大
进一步思考
- 正负样本都是根据特定分布随机出来的
- 数据中存在大量相同的Float值
- 正负样本不平衡 9:1的关系
我们作出了以下特征假设: 对于某个特征 target=1的值为10左右的count数的绝对量要多余target=1的10左右的count数,因为分别roll出来的有独立值,比如10.1只在target=1中,10.2只在target=0中,10.2的绝对count数量要多于10.1的绝对数量。这个10.1就是有问题的值了。
基于这种假设,我们设计了count / dist类型的交叉特征簇,dist是受正态分布启发,表示值距离,用来描述我们的特征假设,dist可以是以下计算方式
- 特征值到该特征min距离
- 特征值到该特征max距离
- 特征值到该特征mean距离
- 特征值到该特征mode距离
- 特征值count密度
这部分属于我们的核心Magic特征,除此之外还进行了大量锦上添花的特征尝试,本地CV和线上的一致表现也验证了我们的猜想。
模型方面我们最好的单模型来自于Lightgbm,本地CV0.925+,优秀的单模型是取得Top排名的必备。我们还开发了NN模型,它表现稍差,但和Lightgbm有良好的差异性,最终stacking后,本地CV0.9261,PB0.925,PR0.9238。
总结
这场比赛是我经历竞争最激烈的一场比赛,对于最终的成绩12th也比较满意,毕竟这场比赛有众多Kaggle GM参与。
对数据的异常现象保持敏感是非常重要的,若能通过数据分析给予异常以合理的解释,数据的真相就呼之欲出了。